By : CyberTech News
Atom was originally developed not to deal with ARM but to usher in a
new type of ultra mobile device. That obviously didn't happen. UMPCs
failed, netbooks were a temporary distraction (albeit profitable for
Intel) and a new generation of smartphones and tablets became the new
face of mobile computing. While Atom will continue to play in the ultra
mobile space, Haswell marks the beginning of something new. Rather than
send its second string player into battle, Intel is starting to prep its
star for ultra mobile work.

Read on for our full analysis of both Haswell as a microprocessor architecture and as a ultra mobile platform.
When I first started writing about x86 CPUs Intel was on the verge of entering the enterprise space with its processors. At the time, Xeon was a new brand, unproven in the market. But it highlighted a key change in Intel's strategy for dominance: leverage consumer microprocessor sales to help support your fabs while making huge margins on lower volume, enterprise parts. In other words, get your volume from the mainstream but make your money in the enterprise. Intel managed to double dip and make money on both ends, it just made substantially more in servers.

Today Intel's magic formula is being threatened. Within 8 years many expect all mainstream computing to move to smartphones, or whatever other ultra portable form factor computing device we're carrying around at that point. To put it in perspective, you'll be able to get something faster than an Ivy Bridge Ultrabook or MacBook Air, in something the size of your smartphone, in fewer than 8 years. The problem from Intel's perspective is that it has no foothold in the smartphone market. Although Medfield is finally shipping, the vast majority of smartphones sold feature ARM based SoCs. If all mainstream client computing moves to smartphones, and Intel doesn't take a dominant portion of the smartphone market, it will be left in the difficult position of having to support fabs that no longer run at the same capacity levels they once did. Without the volume it would become difficult to continue to support the fab business. And without the mainstream volume driving the fabs it would be difficult to continue to support the enterprise business. Intel wouldn't go away, but Wall Street wouldn't be happy. There's a good reason investors have been reaching out to any and everyone to try and get a handle on what is going to happen in the Intel v ARM race.
To make matters worse, there's trouble in paradise. When Apple dropped PowerPC for Intel's architectures back in 2005 I thought the move made tremendous sense. Intel needed a partner that was willing to push the envelope rather than remain content with the status quo. The results of that partnership have been tremendous for both parties. Apple moved aggressively into ultraportables with the MacBook Air, aided by Intel accelerating its small form factor chip packaging roadmap and delivering specially binned low leakage parts. On the flip side, Intel had a very important customer that pushed it to do much better in the graphics department. If you think the current crop of Intel processor graphics aren't enough, you should've seen what Intel originally planned to bring to market prior to receiving feedback from Apple and others. What once was the perfect relationship, is now on rocky ground.
The A6 SoC in Apple's iPhone 5 features the company's first internally designed CPU core. When one of your best customers is dabbling in building CPUs of its own, there's reason to worry. In fact, Apple already makes the bulk of its revenues from ARM based devices. In many ways Apple has been a leading indicator for where the rest of the PC industry is going (shipping SSDs by default, moving to ultra portables as mainstream computers, etc...). There's even more reason to worry if the post-Steve Apple/Intel relationship has fallen on tough times. While I don't share Charlie's view of Apple dropping Intel as being a done deal, I know there's truth behind his words. Intel's Ultrabook push, the close partnership with Acer and working closely with other, non-Apple OEMs is all very deliberate. Intel is always afraid of customers getting too powerful and with Apple, the words too powerful don't even begin to describe it.
What does all of this have to do with Haswell? As I mentioned earlier, Intel has an ARM problem and Apple plays a major role in that ARM problem. Atom was originally developed not to deal with ARM but to usher in a new type of ultra mobile device. That obviously didn't happen. UMPCs failed, netbooks were a temporary distraction (albeit profitable for Intel) and a new generation of smartphones and tablets became the new face of mobile computing. While Atom will continue to play in the ultra mobile space, Haswell marks the beginning of something new. Rather than send its second string player into battle, Intel is starting to prep its star for ultra mobile work.
Platform Retargeting
Since the introduction of Conroe/Merom back in 2006 Intel has been prioritizing notebooks for the majority of its processor designs. The TDP target for these architectures was set around 35 - 45W. Higher and lower TDPs were hit by binning and scaling voltage. The rule of thumb is a single architecture can efficiently cover an order of magnitude of TDPs. In the case of these architectures we saw them scale all the way up to 130W and all the way down to 17W.
At the time I didn't think too much about the new design target, but everything makes a lot more sense now. This isn't a "simple" architectural shift, it's a complete rethinking of how Intel approaches platform design. More importantly than Haswell's 10 - 20W design point, is the new expanded SoC design target. I'll get to the second part shortly.
Platform Power
There will be four client focused categories of Haswell, and I can only talk about three of them now. There are the standard voltage desktop parts, the mobile parts and the ultra-mobile parts: Haswell, Haswell M and Haswell U. There's a fourth category of Haswell that may happen but a lot is still up in the air on that line.
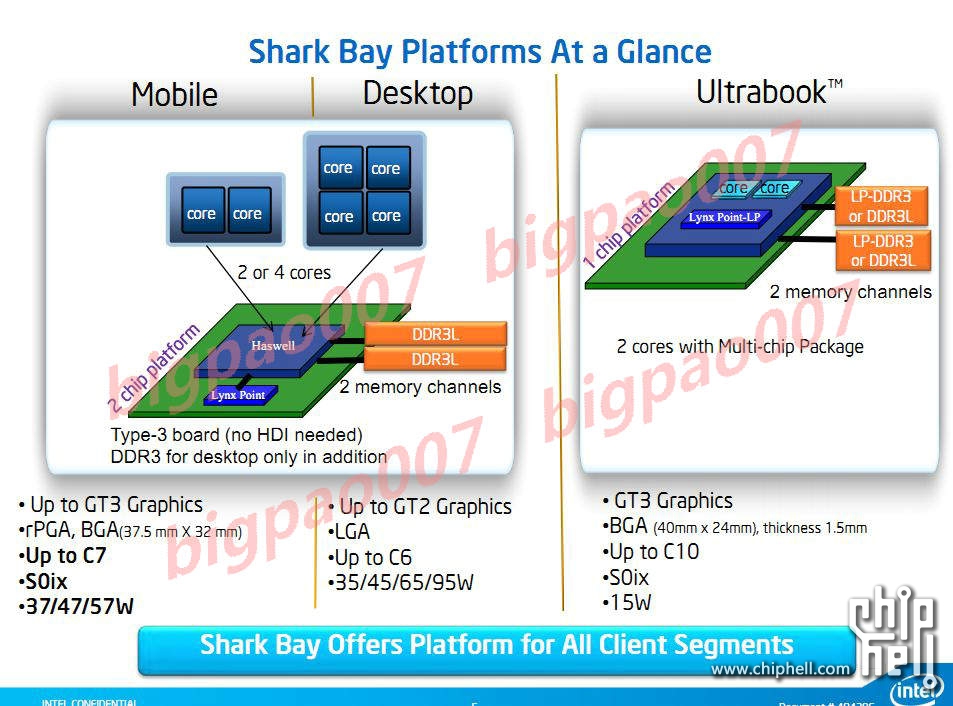
Seven years ago Intel first demonstrated working silicon with an on-chip North Bridge (now commonplace) and on-package CMOS voltage regulation:


2005 - A prototype motherboard using the technology. Note the lack of voltage regulators on the motherboard and the missing GMCH (North Bridge) chip.


The New Sleep States: S0ix
A bunch of PC makers got together and defined the various operating modes that ACPI PCs can be in. If everyone plays by the same rules there are no surprises, which is good for the entire ecosystem.System level power states are denoted S0 - S5. Higher S-numbers indicate deeper levels of sleep. The table below helps define the states:
| ACPI Sleeping State Definitions | ||||
| Sleeping State | Description | |||
| S0 | Awake | |||
| S1 | Low wake latency sleeping state. No system context is lost, hardware maintains all context. | |||
| S2 | Similar to S1 but CPU and system cache context is lost | |||
| S3 | All system context is lost except system memory (CPU, cache, chipset context all lost). | |||
| S4 | Lowest power, longest wake latency supported by ACPI. Hardware platform has powered off all devices, platform context is maintained. | |||
| S5 | Similar so S4 except OS doesn't save any context, requires complete boot upon wake. | |||
These six sleeping states have served the PC well over the years. The addition of S3 gave us fast resume from sleep, something that's often exploited when you're on the go and need to quickly transition between using your notebook and carrying it around. The ultra mobile revolution however gave us a new requirement: the ability to transact data while in an otherwise deep sleep state.
Your smartphone and tablet both fetch emails, grab Twitter updates, receive messages and calls while in their sleep state. The prevalence of always-on wireless connectivity in these devices makes all of this easy, but the PC/smartphone/tablet convergence guarantees that if the PC doesn't adopt similar functionality it won't survive in the new world.
The solution is connected standby or active idle, a feature supported both by Haswell and Clovertrail as well as all of the currently shipping ARM based smartphones and tablets. Today, transitioning into S3 sleep is initiated by closing the lid on your notebook or telling the OS to go to sleep. In Haswell (and Clovertrail), Intel introduced a new S0ix active idle state (there are multiple active idle states, e.g. S0i1, S0i3). These states promise to deliver the same power consumption as S3 sleep, but with a quick enough wake up time to get back into full S0 should you need to do something with your device.
If these states sound familiar it's because Intel first told us about them with Moorestown:

What specifically happens in these active idle power states? In the past Intel focused on driving power down for all of the silicon it owned: the CPU, graphics core, chipset and even WiFi. In order to make active idle a reality, Intel's reach had to extend beyond the components it makes.
With Haswell U/ULT parts, Intel will actually go in and specify recommended components for the rest of the platform. I'm talking about everything from voltage regulators to random microcontrollers on the motherboard. Even more than actual component "suggestions", Intel will also list recommended firmwares for these components. Intel gave one example where an embedded controller on a motherboard was using 30 - 50mW of power. Through some simple firmware changes Intel was able to drop this particular controller's power consumption down to 5mW. It's not rocket science, but this is Intel's way of doing some of the work that its OEM partners should have been doing for the past decade. Apple has done some of this on its own (which is why OS X based notebooks still enjoy tangibly longer idle battery life than their Windows counterparts), but Intel will be offering this to many of its key OEM partners and in a significant way.
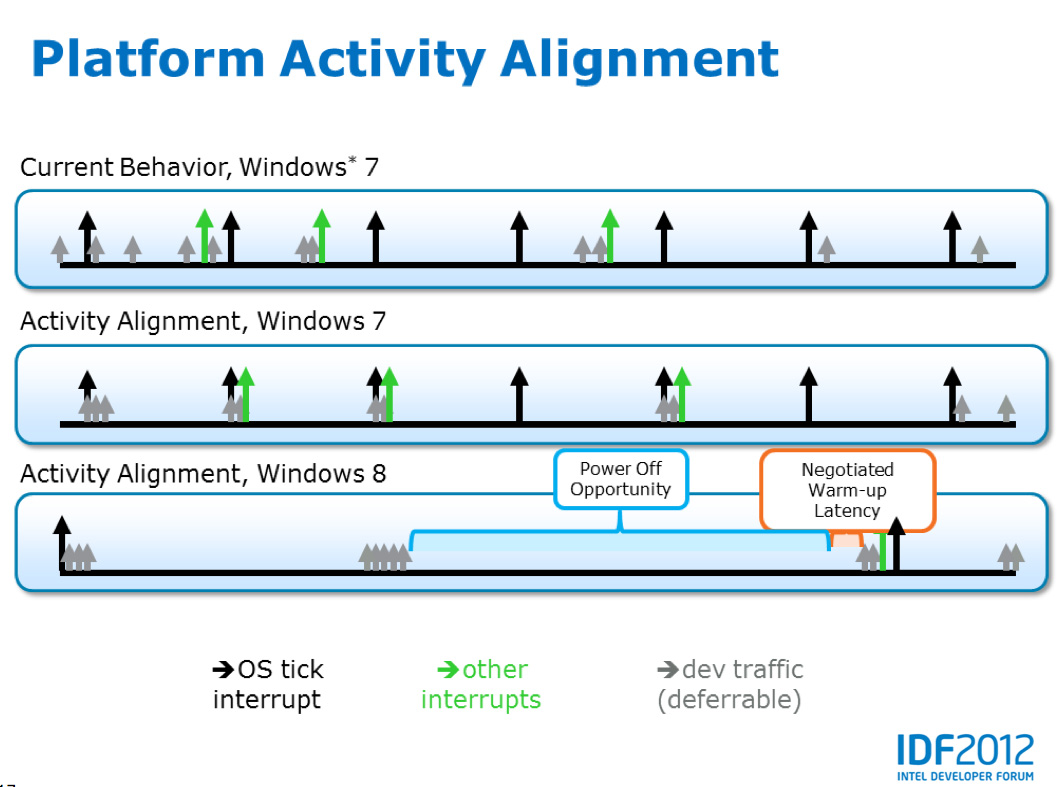
Intel's focus on everything else in the system extends beyond power consumption - it also needs to understand the latency tolerance of everything else in the system. The shift to active idle states is a new way of thinking. In the early days of client computing there was a real focus on allowing all off-CPU controllers to work autonomously. The result of years of evolution along those lines resulted in platforms where any and everything could transact data whenever it wanted to.
By knowing how latency tolerant all of the controllers and components in the system are, hardware and OS platform power management can begin to align traffic better. Rather than everyone transacting data whenever it's ready, all of the components in the system can begin to coalesce their transfers so that the system wakes up for a short period of time to do work then quickly return to sleep. The result is a system that's more frequently asleep with bursts of lots of activity rather than frequently kept awake by small transactions. The diagram below helps illustrate the potential power savings:
All of these platform level power optimizations really focus on components on the motherboard and shaving mWs here and there. There's still one major consumer of power budget that needs addressing as well: the display.
For years Intel has been talking about Panel Self Refresh (PSR) being the holy grail of improving notebook battery life. The concept is simple: even when what's on your display isn't changing (staring at text, looking at your desktop, etc...) the CPU and GPU still have to wake up to refresh the panel 60 times a second. The refresh process isn't incredibly power hungry but it's more wasteful than it needs to be given that no useful work is actually being done.
One solution is PSR. By including a little bit of DRAM on the panel itself, the display could store a copy of the frame buffer. In the event that nothing was changing on the screen, you could put the entire platform to sleep and refresh the panel by looping the same frame data stored in the panel's DRAM. The power savings would be tremendous as it'd allow your entire notebook/tablet/whatever to enter a virtual off state. You could get even more creative and start doing selective PSR where only parts of the display are updated and the rest remain in self-refresh mode (e.g. following a cursor, animating a live tile, etc...).
Similar to what we've seen from Intel in the smartphone and tablet space, you can expect to see reference platforms built around Haswell to show OEMs exactly what they need to put down on a motherboard to deliver the sort of idle power consumption necessary to compete in the new world. It's not clear to me how Intel will enforce these guidelines, although it has a number of tools at its disposal - logo certification being the most obvious.
Page 4
Other Power Savings
Haswell's power savings come from three sources, all of which are equally important. We already went over the most unique: Intel's focus on reducing total platform power consumption by paying attention to everything else on the motherboard (third party controllers, voltage regulation, etc...). The other two sources of power savings are more traditional, but still very significant.
Haswell can also transition between power states approximately 25% faster than Ivy Bridge, which lets the PCU be a bit more aggressive in which power state it selects since the penalty of coming out of it is appreciably lower. It's important to put the timing of all of this in perspective. Putting the CPU cores to sleep and removing voltage/power from them even for a matter of milliseconds adds up to the sort of savings necessary to really enable the sort of always-on, always-connected behavior Haswell based systems are expected to deliver.

The Fourth Haswell
At Computex Intel's Mooly Eden showed off this slide that positioned Haswell as a 15-20W part, while Atom based SoCs would scale up to 10W and perhaps beyond: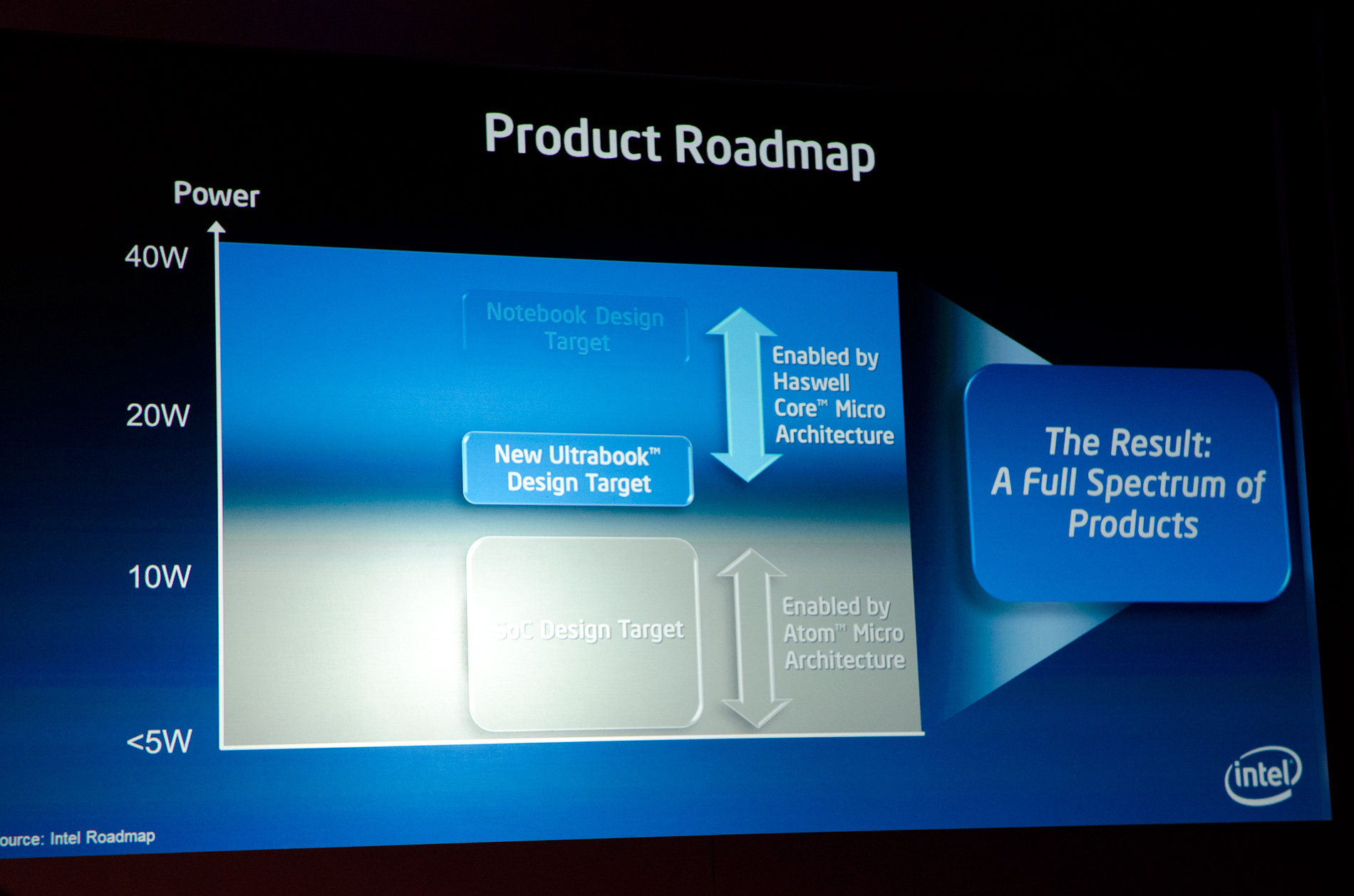

Intel said Haswell can scale below 10W, but it didn't provide a lower bound. It's too much to assume Haswell would go into a phone, but once you get to the 8W point and look south you open yourself up to fitting into things the size of a third generation iPad. Move to 14nm, 10nm and beyond then it becomes more feasible that you could fit this class of architecture into something even more portable.
Intel is being very tight lipped about the fourth client Haswell (remember the first three were desktop, mobile and ultra-low-volt/Ultrabook) but it's clear that it has real aspirations to use it in a space traditionally reserved for ARM or Atom SoCs.
One of the first things I ever heard about Haswell was that it was Intel's solution to the ARM problem. I don't believe a 10W notebook is going to do anything to the ARM problem, but a sub-8W Haswell in an iPad 3 form factor could be very compelling. Haswell won't be fanless, but Broadwell (14nm) could be. And that could be a real solution to the ARM problem, at least outside of a phone.
As I said before, I don't see Haswell making it into a phone but that's not to say a future derivative on a lower power process wouldn't.
CPU Architecture Improvements: Background
Despite all of this platform discussion, we must not forget that
Haswell is the fourth tock since Intel instituted its tick-tock cadence.
If you're not familiar with the terminology by now a tock is a "new"
microprocessor architecture on an existing manufacturing process. In
this case we're talking about Intel's 22nm 3D transistors, that first
debuted with Ivy Bridge. Although Haswell is clearly SoC focused, the
designs we're talking about today all use Intel's 22nm CPU process - not
the 22nm SoC process that has yet to debut for Atom. It's important to
not give Intel too much credit on the manufacturing front. While it has a
full node advantage over the competition in the PC space, it's
currently only shipping a 32nm low power SoC process. Intel may still
have a more power efficient process at 32nm than its other competitors
in the SoC space, but the full node advantage simply doesn't exist there
yet.
 Although Haswell is labeled as a new micro-architecture, it borrows
heavily from those that came before it. Without going into the full
details on how CPUs work I feel like we need a bit of a recap to really
appreciate the changes Intel made to Haswell.
Although Haswell is labeled as a new micro-architecture, it borrows
heavily from those that came before it. Without going into the full
details on how CPUs work I feel like we need a bit of a recap to really
appreciate the changes Intel made to Haswell.
At a high level the goal of a CPU is to grab instructions from memory and execute those instructions. All of the tricks and improvements we see from one generation to the next just help to accomplish that goal faster.
The assembly line analogy for a pipelined microprocessor is over used but that's because it is quite accurate. Rather than seeing one instruction worked on at a time, modern processors feature an assembly line of steps that breaks up the grab/execute process to allow for higher throughput.
The basic pipeline is as follows: fetch, decode, execute, commit to memory. You first fetch the next instruction from memory (there's a counter and pointer that tells the CPU where to find the next instruction). You then decode that instruction into an internally understood format (this is key to enabling backwards compatibility). Next you execute the instruction (this stage, like most here, is split up into fetching data needed by the instruction among other things). Finally you commit the results of that instruction to memory and start the process over again.
Modern CPU pipelines feature many more stages than what I've outlined here. Conroe featured a 14 stage integer pipeline, Nehalem increased that to 16 stages, while Sandy Bridge saw a shift to a 14 - 19 stage pipeline (depending on hit/miss in the decoded uop cache).
The front end is responsible for fetching and decoding instructions, while the back end deals with executing them. The division between the two halves of the CPU pipeline also separates the part of the pipeline that must execute in order from the part that can execute out of order. Instructions have to be fetched and completed in program order (can't click Print until you click File first), but they can be executed in any order possible so long as the result is correct.
Why would you want to execute instructions out of order? It turns out that many instructions are either dependent on one another (e.g. C=A+B followed by E=C+D) or they need data that's not immediately available and has to be fetched from main memory (a process that can take hundreds of cycles, or an eternity in the eyes of the processor). Being able to reorder instructions before they're executed allows the processor to keep doing work rather than just sitting around waiting.
Performance modeling includes current applications of value, future algorithms that you expect to matter when the chip ships as well as insight from key software developers (if Apple and Microsoft tell you that they'll be doing a lot of realistic fur rendering in 4 years, you better make sure your chip is good at what they plan on doing). Obviously you can't predict everything that will happen, so you continue to model and test as new applications and workloads emerge. You feed that data back into the design loop and it continues to influence architectures down the road.
During all of this modeling, even once a design is done, you begin to notice bottlenecks in your design in various workloads. Perhaps you notice that your L1 cache is too small for some newer workloads, or that for a bunch of popular games you're seeing a memory access pattern that your prefetchers don't do a good job of predicting. More fundamentally, maybe you notice that you're decode bound more often than you'd like - or alternatively that you need more integer ALUs or FP hardware. You take this data and feed it back to the team(s) working on future architectures.
The folks working on future architectures then prioritize the wish list and work on including what they can.
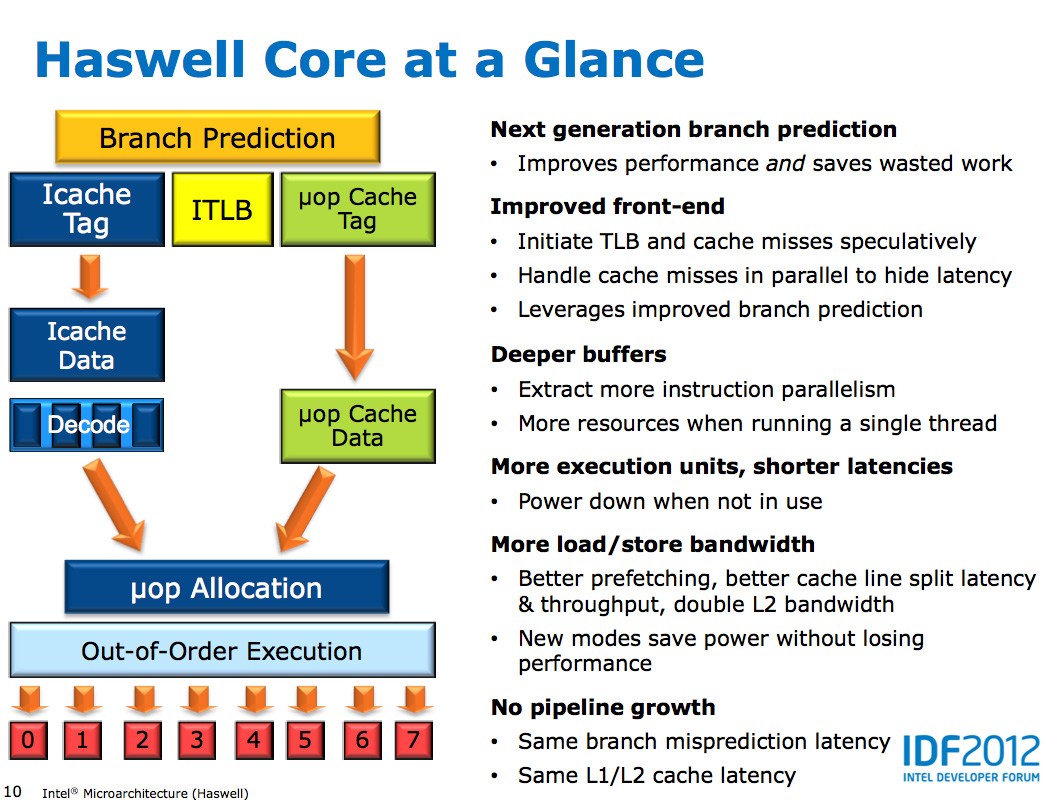
Haswell leaves the overall pipeline untouched. It's still the same 14 - 19 stage pipeline that we saw with Sandy Bridge depending on whether or not the instruction is found in the uop cache (which happens around 80% of the time). L1/L2 cache latencies are unchanged as well. Since Nehalem, Intel's Core micro-architectures have supported execution of two instruction threads per core to improve execution hardware utilization. Haswell also supports 2-way SMT/Hyper Threading.
The front end remains 4-wide, although Haswell features a better branch predictor and hardware prefetcher so we'll see better efficiency. Since the pipeline depth hasn't increased but overall branch prediction accuracy is up we'll see a positive impact on overall IPC (instructions executed per clock). Haswell is also more aggressive on the speculative memory access side.
The image below is a crude representation I put together of the Haswell front end compared to the two previous tocks. If you click the buttons below you'll toggle between Haswell, Sandy Bridge and Nehalem diagrams, with major changes highlighted.

In short, there aren't many major, high-level changes to see here.
Instructions are fetched at the top, sent through a bunch of steps
before getting to the decoders where they're converted from macro-ops
(x86 instructions) to an internally understood format known to Intel as
micro-ops (or µops). The instruction fetcher can grab 4 - 5 x86
instructions at a time, and the decoders can output up to 4 micro-ops
per clock.
Sandy Bridge introduced the 1.5K µop cache that caches decoded micro-ops. When future instruction fetch requests are made, if the instructions are contained within the µop cache everything north of the cache is powered down and the instructions are serviced from the µop cache. The decode stages are very power hungry so being able to skip them is a boon to power efficiency. There are also performance benefits as well. A hit in the µop cache reduces the effective integer pipeline to 14 stages, the same length as it was in Conroe in 2006. Haswell retains all of these benefits. Even the µop cache size remains unchanged at 1.5K micro-ops (approximately 6KB in size).
Although it's noted above as a new/changed block, the updated instruction decode queue (aka allocation queue) was actually one of the changes made to improve single threaded performance in Ivy Bridge.
The instruction decode queue (where instructions go after they've been decoded) is no longer statically partitioned between the two threads that each core can service.
The big changes in Haswell are at the back end of the pipeline, in the execution engine.
Increasing the OoO window allows the execution units to extract more
parallelism and thus improve single threaded performance. Each
generation Intel is simply dedicating additional transistors to
increasing these structures and thus better feeding the beast.
This isn't rocket science, but it is enabled by Intel's clockwork fab execution. Designers can count on another 30% die area to work with every 2 years, so every 2 years they increase the size of these structures without worrying about ballooning the die. The beauty of evolutionary improvements like this is that when viewed over the long term they look downright revolutionary. Comparing Haswell to Conroe, the OoO scheduling window has grown by a factor of 2x, despite generation to generation gains of only 14 - 33%.

Just as before, I put together a few diagrams that highlight the major differences throughout the past three generations for the execution engine.

The reorder buffer is one giant tracking structure for all of the
micro-ops that are in various stages of execution. The size of this
buffer is directly impacted by the accuracy of the branch predictor as
that will determine how many instructions can be kept in flight at a
given time.
The reservation station holds micro-ops as they wait for the data they need to begin execution. Both of these structures grow by low double-digit percentages in Haswell.
Simply being able to pick from more instructions to execute in parallel is one thing, we haven't seen an increase in the number of parallel execution ports since Conroe. Haswell changes that.
From Conroe to Ivy Bridge, Intel's Core micro-architecture has supported the execution of up to six micro-ops in parallel. While there are more than six execution units in the system, there are only six ports to stacks of execution units. Three ports are used for memory operations (loads/stores) while three are on math duty. Over the years Intel has added additional types and widths of execution units (e.g. Sandy Bridge added 256-bit AVX operations) but it hasn't strayed from the 6 port architecture.
Haswell finally adds two more execution ports, one for integer math and branches (port 6) and one for store address calculation (port 7). Including both additional compute and memory hardware is a balanced decision on Intel's part.
The extra ALU and port does one of two things: either improve performance for integer heavy code, or allow integer work to continue while FP math occupies ports 0 and 1. Remember that Haswell, like its predecessors, is an SMT design meaning each core will see instructions from up to two threads at the same time. Although a single app is unlikely to mix heavy vector FP and integer code, it's quite possible that two applications running at the same time may produce such varied instructions. Having more integer ALUs is never a bad thing.
Also using port 6 is another unit that can handle x86 branch instructions. Branch heavy code can now enjoy two independent branch units, or if port 0 is occupied with other math the machine can still execute branches on port 6. Haswell moved the original Core branch unit from port 5 over to port 0, the most capable port in the system, so a branch unit on a lightly populated port makes helps ensure there's no performance regression as a result of the change.
Sandy Bridge made ports 2 & 3 equal class citizens, with both capable of being used for load or store address calculation. In the past you could only do loads on port 2 and store addresses on port 3. Sandy Bridge's flexibility did a lot for load heavy code, which is quite common. Haswell's dedicated store address port should help in mixed workloads with lots of loads and stores.
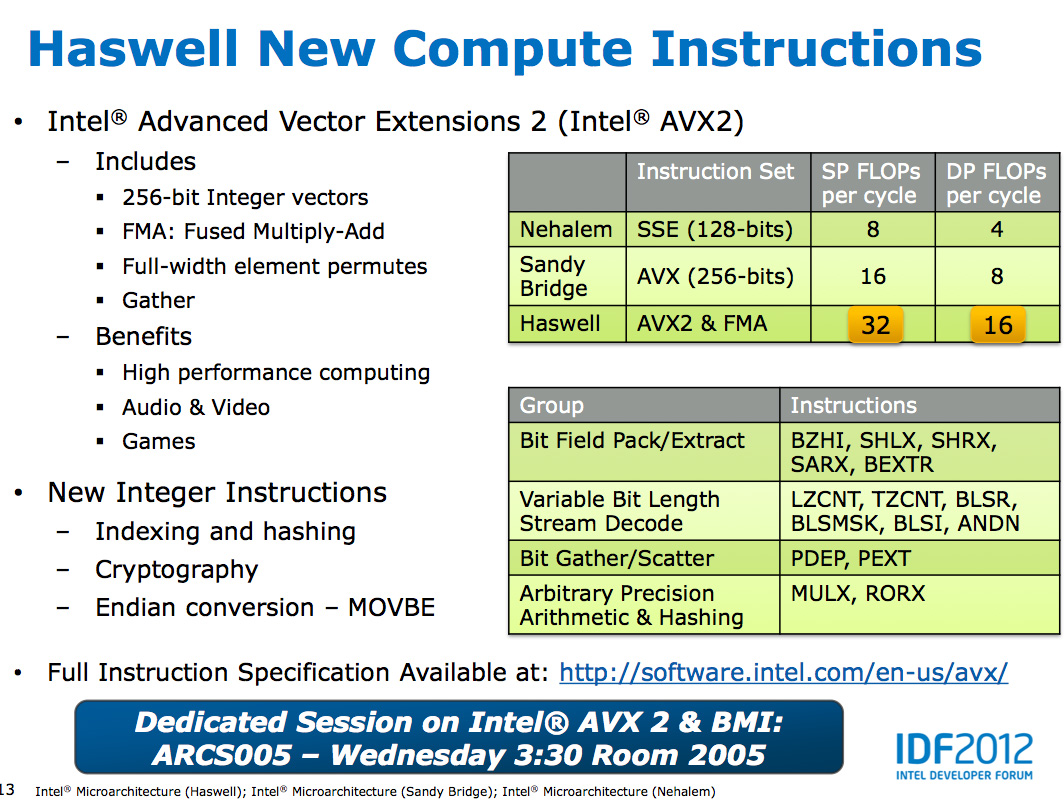
 The other major addition to the execution engine is support for Intel's
AVX2 instructions, including FMA (Fused Multiply-Add). Ports 0 & 1
now include newly designed 256-bit FMA units. As each FMA operation is
effectively two floating point operations, these two units double the
peak floating point throughput of Haswell compared to Sandy/Ivy Bridge. A
side effect of the FMA units is that you now get two ports worth of FP
multiply units, which can be a big boon to legacy FP code.
The other major addition to the execution engine is support for Intel's
AVX2 instructions, including FMA (Fused Multiply-Add). Ports 0 & 1
now include newly designed 256-bit FMA units. As each FMA operation is
effectively two floating point operations, these two units double the
peak floating point throughput of Haswell compared to Sandy/Ivy Bridge. A
side effect of the FMA units is that you now get two ports worth of FP
multiply units, which can be a big boon to legacy FP code.
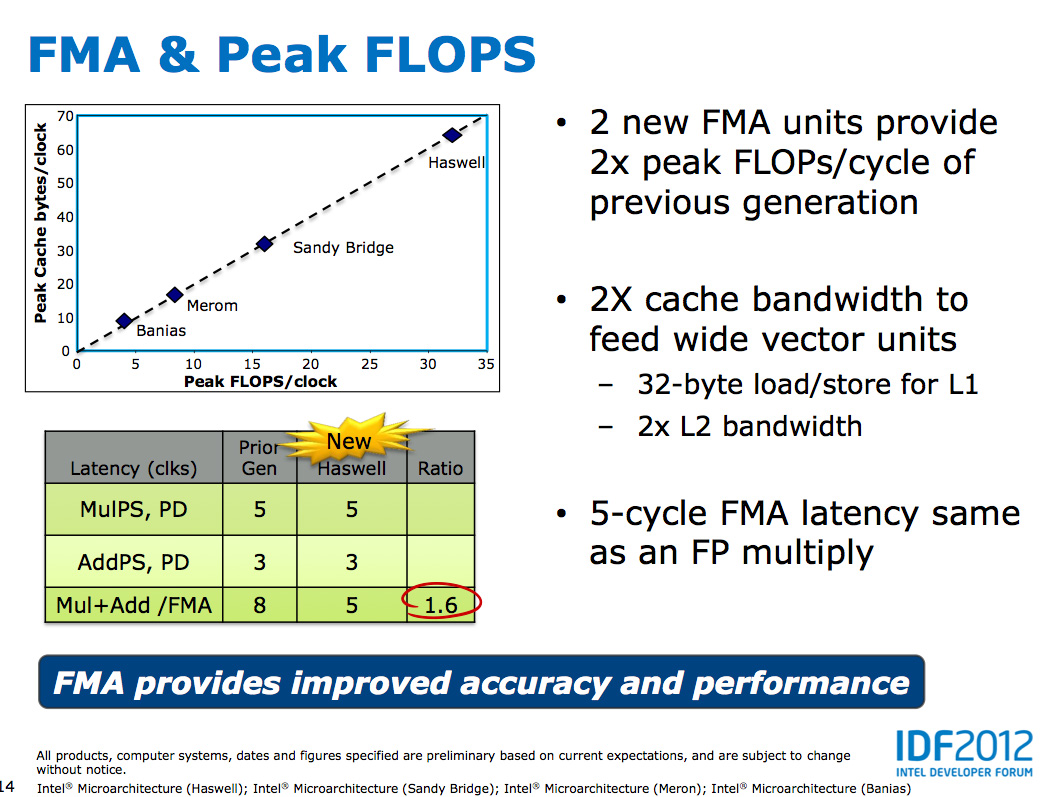
 Fused Multiply-Add operations are incredibly handy in all sorts of
media processing and 3D work. Rather than having to independently
multiply and add values, being able to execute both in tandem via a
single execution port increases the effective execution width of the
machine. Note that a single FMA operation takes 5 cycles in Haswell,
which is the same latency as a FP multiply from Sandy/Ivy Bridge. In the
previous generation a floating point multiply+add took 8 cycles, so
there's a good latency improvement here as well as the throughput boost
from having two FMA units.
Fused Multiply-Add operations are incredibly handy in all sorts of
media processing and 3D work. Rather than having to independently
multiply and add values, being able to execute both in tandem via a
single execution port increases the effective execution width of the
machine. Note that a single FMA operation takes 5 cycles in Haswell,
which is the same latency as a FP multiply from Sandy/Ivy Bridge. In the
previous generation a floating point multiply+add took 8 cycles, so
there's a good latency improvement here as well as the throughput boost
from having two FMA units.
 Intel focused a lot on adding more execution horsepower in Haswell
without creating a power burden for legacy use cases. All of the new
units can be shut off when not in use. Furthermore, Intel went in and
ensured that this applied to the older execution units as well: in
Haswell if you're not doing work, you're not consuming power.
Intel focused a lot on adding more execution horsepower in Haswell
without creating a power burden for legacy use cases. All of the new
units can be shut off when not in use. Furthermore, Intel went in and
ensured that this applied to the older execution units as well: in
Haswell if you're not doing work, you're not consuming power.
 L1/L2 cache latencies and sizes remain unchanged. The same isn't true for the L3 cache however.
L1/L2 cache latencies and sizes remain unchanged. The same isn't true for the L3 cache however.
In Sandy Bridge, Intel revised its beliefs and moved to a single clock domain for the core and uncore, while keeping a separate clock for the now on-die processor graphics core. Intel now felt that race to sleep was a better philosophy for dealing with the L3 cache and it would rather keep things simple by running everything at the same frequency. Obviously there are performance benefits, but there was one major downside: with the CPU cores and L3 cache running in lockstep, there was concern over what would happen if the GPU ever needed to access the L3 cache while the CPU (and thus L3 cache) was in a low frequency state. The options were either to force the CPU and L3 cache into a higher frequency state together, or to keep the L3 cache at a low frequency even when it was in demand to prevent waking up the CPU cores. Ivy Bridge saw the addition of a small graphics L3 cache to mitigate this situation, but ultimately giving the on-die GPU independent access to the big, primary L3 cache without worrying about power concerns was a big issue for the design team.
 When it came time to define Haswell, the engineers once again went to
Nehalem's three clock domains. Ronak (Nehalem & Haswell architect,
insanely smart guy) tells me that the switching between designs is
simply a product of the team learning more about the architecture and
understanding the best balance. I think it tells me that these guys are
still human and don't always have the right answer for the long term
without some trial and error.
When it came time to define Haswell, the engineers once again went to
Nehalem's three clock domains. Ronak (Nehalem & Haswell architect,
insanely smart guy) tells me that the switching between designs is
simply a product of the team learning more about the architecture and
understanding the best balance. I think it tells me that these guys are
still human and don't always have the right answer for the long term
without some trial and error.
The three clock domains in Haswell are roughly the same as what they were in Nehalem, they just all happen to be on the same die. The CPU cores all run at the same frequency, the on-die GPU runs at a separate frequency and now the L3 + ring bus are in their own independent frequency domain.
Now that CPU requests to L3 cache have to cross a frequency boundary there will be a latency impact to L3 cache accesses. Sandy Bridge had an amazingly fast L3 cache, Haswell's L3 accesses will be slower.
The benefit is obviously power. If the GPU needs to fire up the ring bus to give/get data, it no longer has to drive up the CPU core frequency as well. Furthermore, Haswell's power control unit can dynamically allocate budget between all areas of the chip when power limited.
Although L3 latency is up in Haswell, there's more access bandwidth offered to each slice of the L3 cache. There are now dedicated pipes for data and non-data accesses to the last level cache.
Haswell's memory controller is also improved, with better write throughput to DRAM. Intel has been quietly telling the memory makers to push for even higher DDR3 frequencies in anticipation of Haswell.
It's easy to demand well threaded applications from software vendors, but actually implementing code that scales well across unlimited threads isn't easy. Parallelizing truly independent tasks is the low hanging fruit, but it's the tasks that all access the same data structure that can create problems. With multiple cores accessing the same data structure, running independent of one another, there's the risk of two different cores writing to the same part of the same structure. Only one set of data can be right, but dealing with this concurrent access problem can get hairy.
 The simplest way to deal with it is simply to lock the entire data
structure as soon as one core starts accessing it and only allow that
one core write access until it's done. Other cores are given access to
the data structure, but serially, not in parallel to avoid any data
integrity issues.
The simplest way to deal with it is simply to lock the entire data
structure as soon as one core starts accessing it and only allow that
one core write access until it's done. Other cores are given access to
the data structure, but serially, not in parallel to avoid any data
integrity issues.
This is by far the easiest way to deal with the problem of multiple threads accessing the same data structure, however it also prevents any performance scaling across multiple threads/cores. As focused as Intel is on increasing single threaded performance, a lot of die area goes wasted if applications don't scale well with more cores.
Software developers can instead choose to implement more fine grained locking of data structures, however doing so obviously increases the complexity of their code.
 Haswell's TSX instructions allow the developer to shift much of the
complexity of managing locks to the CPU. Using the new Hardware Lock
Elision and its XAQUIRE/XRELEASE instructions, Haswell developers can
mark a section of code for transactional execution. Haswell will then
execute the code as if no hardware locks were in place and if it
completes without issues the CPU will commit all writes to memory and
enjoy the performance benefits. If two or more threads attempt to write
to the same area in memory, the process is aborted and code re-executed
traditionally with locks. The XAQUIRE/XRELEASE instructions decode to
no-ops on earlier architectures so backwards compatibility isn't a
problem.
Haswell's TSX instructions allow the developer to shift much of the
complexity of managing locks to the CPU. Using the new Hardware Lock
Elision and its XAQUIRE/XRELEASE instructions, Haswell developers can
mark a section of code for transactional execution. Haswell will then
execute the code as if no hardware locks were in place and if it
completes without issues the CPU will commit all writes to memory and
enjoy the performance benefits. If two or more threads attempt to write
to the same area in memory, the process is aborted and code re-executed
traditionally with locks. The XAQUIRE/XRELEASE instructions decode to
no-ops on earlier architectures so backwards compatibility isn't a
problem.
 Like most new instructions, it's going to take a while for Haswell's
TSX to take off as we'll need to see significant adoption of Haswell
platforms as well as developers embracing the new instructions. TSX does
stand to show improvements in performance anywhere from client to
server performance if implemented however, this is definitely one to
watch for and be excited about.
Like most new instructions, it's going to take a while for Haswell's
TSX to take off as we'll need to see significant adoption of Haswell
platforms as well as developers embracing the new instructions. TSX does
stand to show improvements in performance anywhere from client to
server performance if implemented however, this is definitely one to
watch for and be excited about.
 Haswell also continues improvements in virtualization performance, including big increases to guest/host transition times.
Haswell also continues improvements in virtualization performance, including big increases to guest/host transition times.
Haswell builds on the same fundamental GPU architecture we saw in Ivy Bridge. We won't see a dramatic redesign/re-plumbing of the graphics hardware until Broadwell in 2014 (that one is going to be a big one).
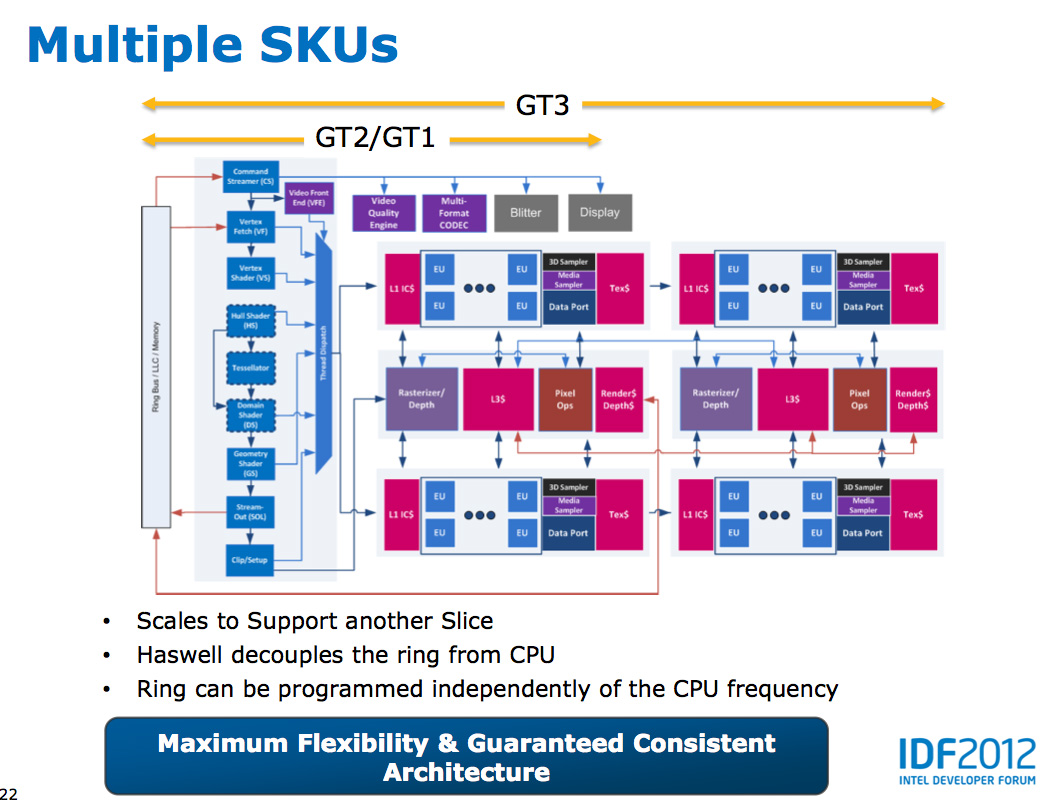
 Haswell's GPU will be available in three physical configurations:
GT1, GT2 and GT3. Although Intel mentioned that the Haswell GT3 config
would have twice the shader count of Haswell GT2, it was careful not to
disclose the total number of EUs in any of the versions. Based on the
information we have at this point, GT3 should be a 40 EU configuration
while GT2 should feature 20 EUs. Intel will also be including up to one
redundant EU to deal with the case where there's a defect in an EU in
the array. This isn't an uncommon practice, but it does indicate just
how much of the die will be dedicated to graphics in Haswell. The larger
of an area the GPU covers, the greater the likelihood that you'll see
unrecoverable defects in the GPU. Redundancy at the EU level is one way
of mitigating that problem.
Haswell's GPU will be available in three physical configurations:
GT1, GT2 and GT3. Although Intel mentioned that the Haswell GT3 config
would have twice the shader count of Haswell GT2, it was careful not to
disclose the total number of EUs in any of the versions. Based on the
information we have at this point, GT3 should be a 40 EU configuration
while GT2 should feature 20 EUs. Intel will also be including up to one
redundant EU to deal with the case where there's a defect in an EU in
the array. This isn't an uncommon practice, but it does indicate just
how much of the die will be dedicated to graphics in Haswell. The larger
of an area the GPU covers, the greater the likelihood that you'll see
unrecoverable defects in the GPU. Redundancy at the EU level is one way
of mitigating that problem.
Haswell's processor graphics extends API support to DirectX 11.1, OpenCL 1.2 and OpenGL 4.0.
At the front of the graphics pipeline is a new resource streamer. The RS offloads some driver work that the CPU would normally handle and moves it to GPU hardware instead. Both AMD and NVIDIA have significant command processors so this doesn't appear to be an Intel advantage although the devil is in the (unshared) details. The point from Intel's perspective is that any amount of processing it can shift away from general purpose CPU hardware and onto the GPU can save power (CPU cores go to sleep while the RS/CS do their job).
Beyond the resource streamer, most of the fixed function graphics hardware sees a doubling of performance in Haswell.
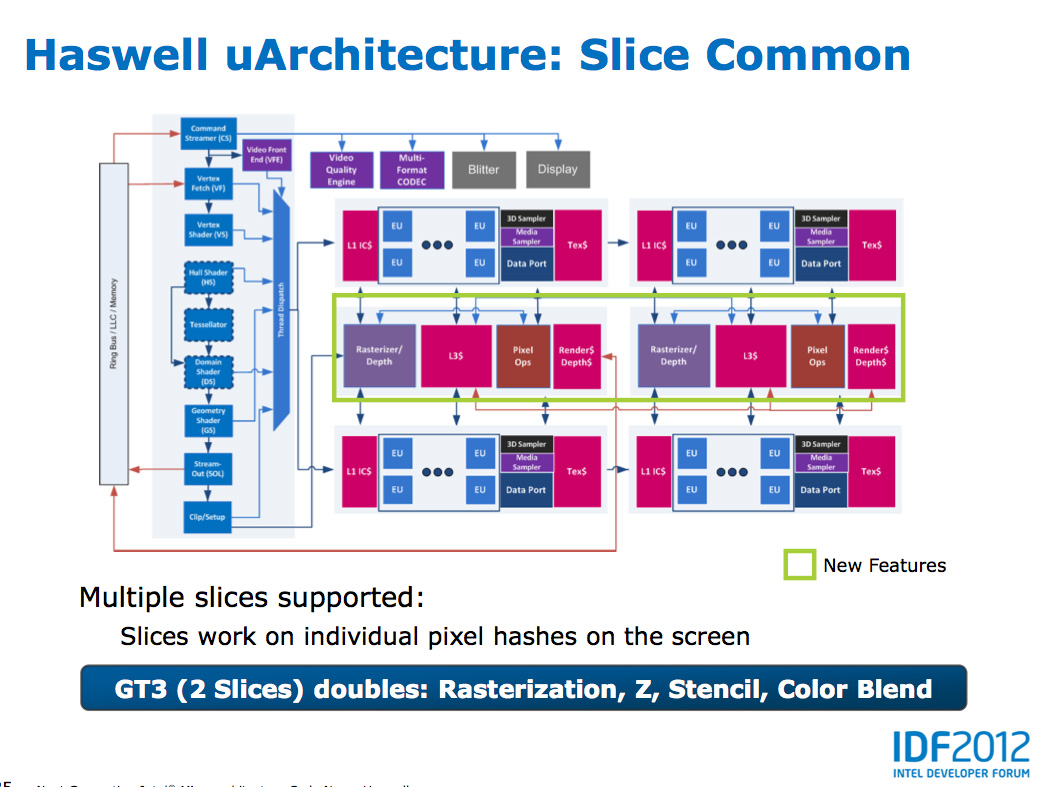
 At the shader core level, Intel separates the GPU design into two
sections: slice common and sub-slice. Slice common includes the
rasterizer, pixel back end and GPU L3 cache. The sub-slice includes all
of the EUs, instruction caches and EUs.
At the shader core level, Intel separates the GPU design into two
sections: slice common and sub-slice. Slice common includes the
rasterizer, pixel back end and GPU L3 cache. The sub-slice includes all
of the EUs, instruction caches and EUs.
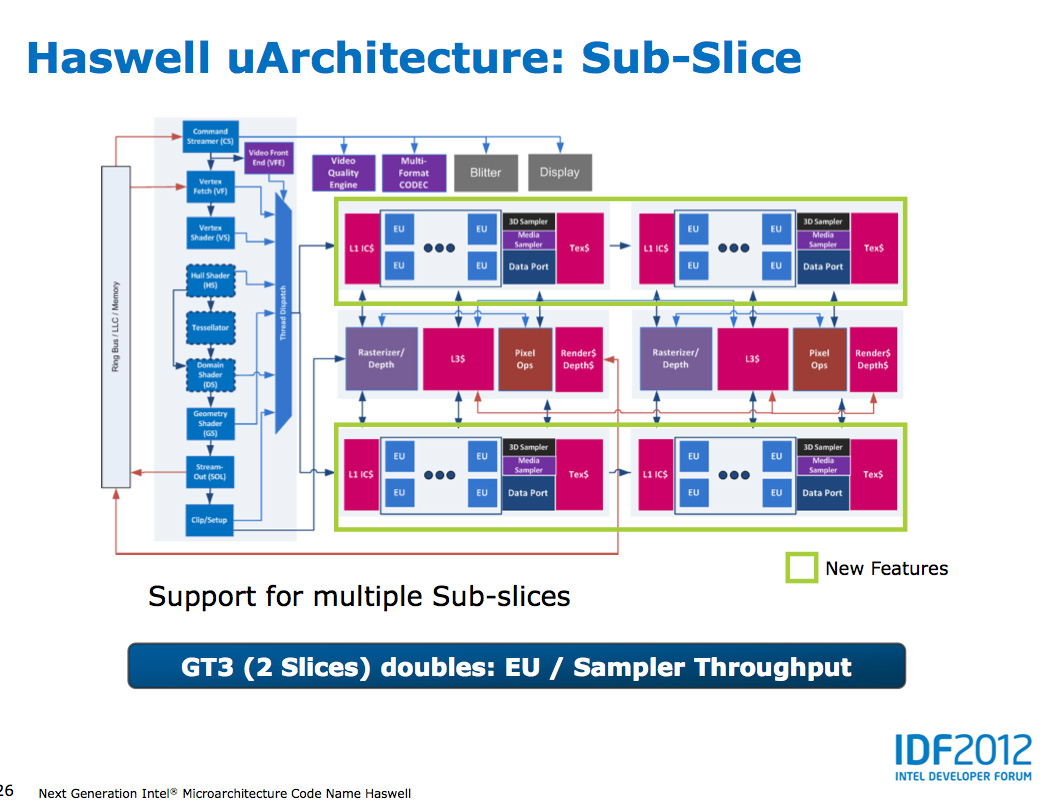
In Haswell GT1 and GT2 there's a single slice common, while GT3 sees a doubling of slice common. GT3 similarly has two sub-slices, although once again Intel isn't talking specifics about EU counts or clock speeds between GT1/2/3.
 The final bit of detail Intel gave out about Haswell's GPU is the
texture sampler sees up to a 4x improvement in throughput over Ivy
Bridge in some modes.
The final bit of detail Intel gave out about Haswell's GPU is the
texture sampler sees up to a 4x improvement in throughput over Ivy
Bridge in some modes.
Now to the things that Intel didn't let loose at IDF. Although originally an option for Ivy Bridge (but higher ups at Intel killed plans for it) was a GT3 part with some form of embedded DRAM. Rumor has it that Apple was the only customer who really demanded it at the time, and Intel wasn't willing to build a SKU just for Apple.
Haswell will do what Ivy Bridge didn't. You'll see a version of Haswell with up to 128MB of embedded DRAM, with a lot of bandwidth available between it and the core. Both the CPU and GPU will be able to access this embedded DRAM, although there are obvious implications for graphics.
Overall performance gains should be about 2x for GT3 (presumably with eDRAM) over HD 4000 in a high TDP part. In Ultrabooks those gains will be limited to around 30% max given the strict power limits.
 As for why Intel isn't talking about embedded DRAM on Haswell, your
guess is as good as mine. The likely release timeframe for Haswell is
close to June 2013, there's still tons of time between now and then. It
looks like Intel still has a desire to remain quiet on some fronts.
As for why Intel isn't talking about embedded DRAM on Haswell, your
guess is as good as mine. The likely release timeframe for Haswell is
close to June 2013, there's still tons of time between now and then. It
looks like Intel still has a desire to remain quiet on some fronts.
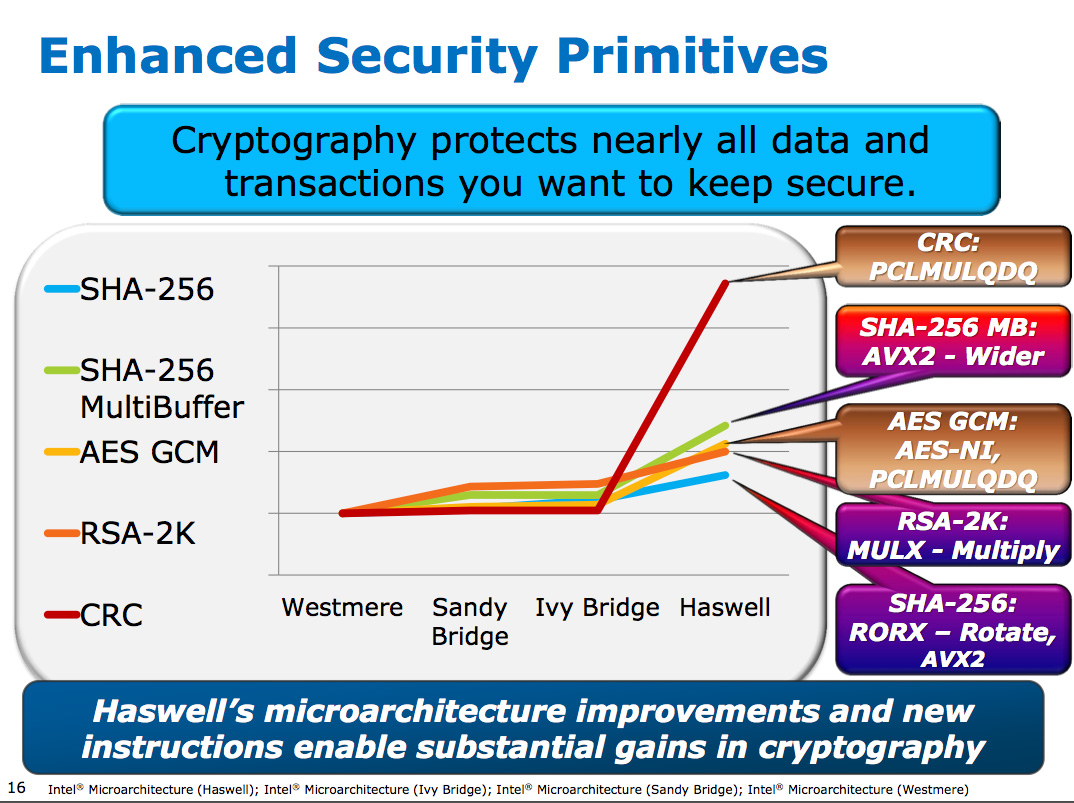
 First and foremost is hardware support for the SVC (Scalable Video
Coding) codec. The idea behind SVC is to take one high resolution
bitstream from which lower quality versions can be derived. There are
huge implications for SVC in applications that have varied bandwidth
levels and/or decode capabilities.
First and foremost is hardware support for the SVC (Scalable Video
Coding) codec. The idea behind SVC is to take one high resolution
bitstream from which lower quality versions can be derived. There are
huge implications for SVC in applications that have varied bandwidth
levels and/or decode capabilities.
Haswell also adds a hardware motion JPEG decoder, and MPEG2 hardware encoder.
Ivy Bridge will be getting 4K video playback support later this year, Haswell should obviously ship with it.
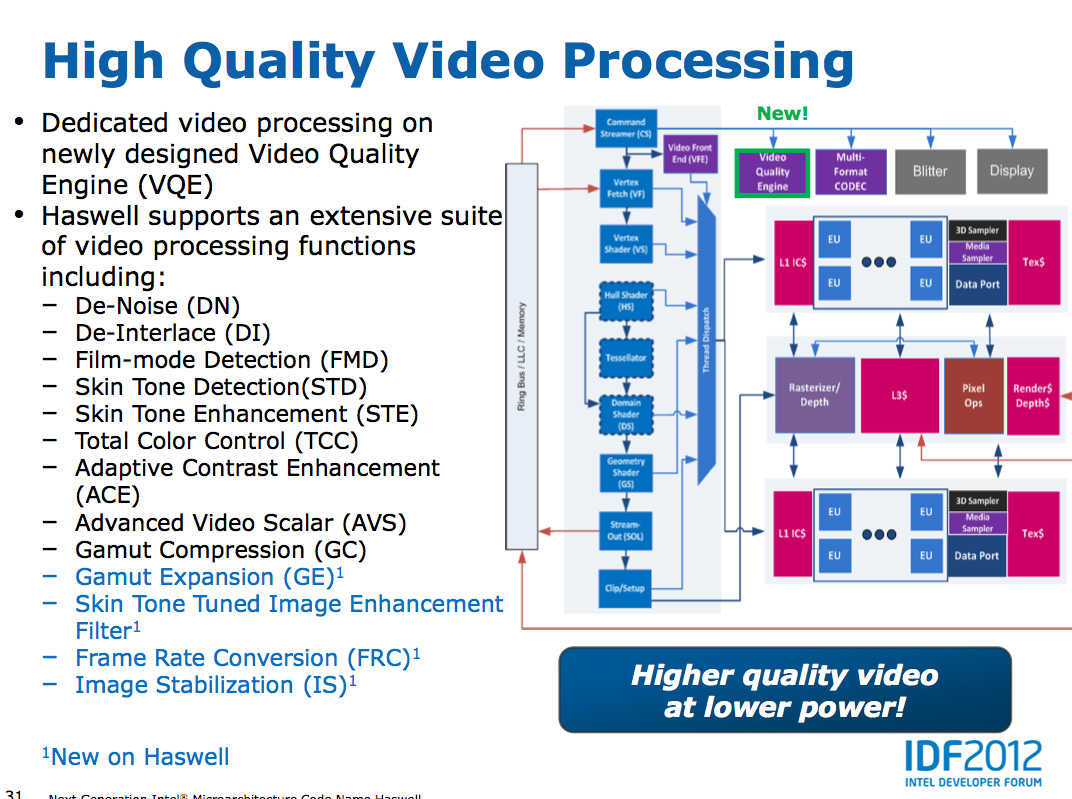
 Finally there's a greater focus on image quality this generation,
although as I mentioned before I'm not sure we'll see official support
in a lot of the open source video codecs until Broadwell comes by. With
added EUs we'll obviously see QuickSync performance improve, but I don't
have data as to how much faster it'll be compared to Ivy Bridge.
Finally there's a greater focus on image quality this generation,
although as I mentioned before I'm not sure we'll see official support
in a lot of the open source video codecs until Broadwell comes by. With
added EUs we'll obviously see QuickSync performance improve, but I don't
have data as to how much faster it'll be compared to Ivy Bridge.

 There are three conclusions that have to be made when it comes to
Haswell: its CPU architecture, its platform architecture and what it
means for Intel's future. Two of the three look good from my
perspective. The third one is not so clear.
There are three conclusions that have to be made when it comes to
Haswell: its CPU architecture, its platform architecture and what it
means for Intel's future. Two of the three look good from my
perspective. The third one is not so clear.
Intel's execution has been relentless since 2006. That's over half a decade of iterating architectures, as promised, roughly once a year. Little, big, little, big, process, architecture, process, architecture, over and over again. It's a combination of great execution on the architecture side combined with great enabling by Intel's manufacturing group. Haswell will continue to carry the torch in this regard.
The Haswell micro-architecture focuses primarily on widening the execution engine that has been with us, moderately changed, for the past several years. Increasing data structures and buffers inside the processor helps to feed the beast, as does a tremendous increase in cache bandwidth. Support for new instructions in AVX2 via Intel's TSX should also pave the way for some big performance gains going forward. Power consumption is also a serious target for Haswell given that it must improve performance without dramatically increasing TDP (there will be slight increases across the board for traditional form factors, while ultra portables will obviously shift to lower TDPs).
You can expect CPU performance to increase by around 5 - 15% at the same clock speed as Ivy Bridge. Graphics performance will see a far larger boost (at least in the high-end GT3 configuration) of up to 2x vs. Intel's HD 4000 in a standard voltage/TDP system. GPU performance in Ultrabooks will increase by up to 30% over HD 4000.
As a desktop or notebook microprocessor, Haswell looks very good. The architecture remains focused and delivers a sensible set of improvements over its predecessor.
 As a platform, Haswell looks awesome. While the standard Haswell parts
won't drive platform power down considerably, the new Haswell U/ULT
parts will. Intel is promising a greater than 20x reduction in platform
idle power and it's planning on delivering it by focusing its power
reduction efforts beyond Intel manufactured components. Haswell
Ultrabooks and tablets will have Intel's influence in many (most?) of
the components placed on the motherboard. And honestly, this is
something Intel (or one of its OEMs) should have done long ago. Driving
down platform power is a problem that extends beyond the CPU or chipset,
and it's one that requires a holistic solution. With Haswell, Intel
appears committed to delivering that solution. It's not for purely
altruistic reasons, but for the survival of the PC. I remember talking
to Vivek about an iPad as a notebook replacement piece he was doing a
while back. The biggest advantage the iPad offered over a notebook in
his eyes? Battery life. Even for light workloads today's most power
efficient ultraportable notebooks can't touch a good ARM based tablet.
Haswell U/ULT's significant reduction in platform power is intended to
fix that. I don't know that we'll get to 10+ hours of battery life on a
single charge, but we should be much better off than we are today.
As a platform, Haswell looks awesome. While the standard Haswell parts
won't drive platform power down considerably, the new Haswell U/ULT
parts will. Intel is promising a greater than 20x reduction in platform
idle power and it's planning on delivering it by focusing its power
reduction efforts beyond Intel manufactured components. Haswell
Ultrabooks and tablets will have Intel's influence in many (most?) of
the components placed on the motherboard. And honestly, this is
something Intel (or one of its OEMs) should have done long ago. Driving
down platform power is a problem that extends beyond the CPU or chipset,
and it's one that requires a holistic solution. With Haswell, Intel
appears committed to delivering that solution. It's not for purely
altruistic reasons, but for the survival of the PC. I remember talking
to Vivek about an iPad as a notebook replacement piece he was doing a
while back. The biggest advantage the iPad offered over a notebook in
his eyes? Battery life. Even for light workloads today's most power
efficient ultraportable notebooks can't touch a good ARM based tablet.
Haswell U/ULT's significant reduction in platform power is intended to
fix that. I don't know that we'll get to 10+ hours of battery life on a
single charge, but we should be much better off than we are today.
Connected standby is coming to PCs and it's a truly necessary addition. Haswell's support of active idle states (S0ix) is a game changer for the way portable PCs work. The bigger concern is whether or not the OEMs and ISVs will do their best to really take advantage of what Haswell offers. I know one will, but will the rest? Intel's increasingly hands on approach to OEM relations seems to be its way of ensuring we'll see Haswell live up to its potential.
Haswell, on paper, appears to do everything Intel needs to evolve the mobile PC platform. What's unclear is how far down the TDP stack Intel will be able to take the architecture. Intel seems to believe that TDPs below 8W are attainable, but it's too early to tell just how low Haswell can go. It's more than likely that Intel knows and just doesn't want to share at this point. I don't believe we'll see fanless Haswell designs, but Broadwell is another story entirely.
There's no diagram for where we go from here. Intel originally claimed that Atom would service an expanded range of TDPs all the way up to 10W. With Core architectures dipping below 10W, I do wonder if that slide was a bit of misdirection. I wonder if, instead, the real goal is to drive Core well into Atom territory. If Intel wants to solve its ARM problem, that would appear to be a very good solution...
Source : Anand Tech
At a high level the goal of a CPU is to grab instructions from memory and execute those instructions. All of the tricks and improvements we see from one generation to the next just help to accomplish that goal faster.
The assembly line analogy for a pipelined microprocessor is over used but that's because it is quite accurate. Rather than seeing one instruction worked on at a time, modern processors feature an assembly line of steps that breaks up the grab/execute process to allow for higher throughput.
The basic pipeline is as follows: fetch, decode, execute, commit to memory. You first fetch the next instruction from memory (there's a counter and pointer that tells the CPU where to find the next instruction). You then decode that instruction into an internally understood format (this is key to enabling backwards compatibility). Next you execute the instruction (this stage, like most here, is split up into fetching data needed by the instruction among other things). Finally you commit the results of that instruction to memory and start the process over again.
Modern CPU pipelines feature many more stages than what I've outlined here. Conroe featured a 14 stage integer pipeline, Nehalem increased that to 16 stages, while Sandy Bridge saw a shift to a 14 - 19 stage pipeline (depending on hit/miss in the decoded uop cache).
The front end is responsible for fetching and decoding instructions, while the back end deals with executing them. The division between the two halves of the CPU pipeline also separates the part of the pipeline that must execute in order from the part that can execute out of order. Instructions have to be fetched and completed in program order (can't click Print until you click File first), but they can be executed in any order possible so long as the result is correct.
Why would you want to execute instructions out of order? It turns out that many instructions are either dependent on one another (e.g. C=A+B followed by E=C+D) or they need data that's not immediately available and has to be fetched from main memory (a process that can take hundreds of cycles, or an eternity in the eyes of the processor). Being able to reorder instructions before they're executed allows the processor to keep doing work rather than just sitting around waiting.
Sidebar on Performance Modeling
Microprocessor design is one giant balancing act. You model application performance and build the best architecture you can in a given die area for those applications. Tradeoffs are inevitably made as designers are bound by power, area and schedule constraints. You do the best you can this generation and try to get the low hanging fruit next time.Performance modeling includes current applications of value, future algorithms that you expect to matter when the chip ships as well as insight from key software developers (if Apple and Microsoft tell you that they'll be doing a lot of realistic fur rendering in 4 years, you better make sure your chip is good at what they plan on doing). Obviously you can't predict everything that will happen, so you continue to model and test as new applications and workloads emerge. You feed that data back into the design loop and it continues to influence architectures down the road.
During all of this modeling, even once a design is done, you begin to notice bottlenecks in your design in various workloads. Perhaps you notice that your L1 cache is too small for some newer workloads, or that for a bunch of popular games you're seeing a memory access pattern that your prefetchers don't do a good job of predicting. More fundamentally, maybe you notice that you're decode bound more often than you'd like - or alternatively that you need more integer ALUs or FP hardware. You take this data and feed it back to the team(s) working on future architectures.
The folks working on future architectures then prioritize the wish list and work on including what they can.
Page 6
The Haswell Front End
Conroe was a very wide machine. It brought us the first 4-wide front end of any x86 micro-architecture, meaning it could fetch and decode up to 4 instructions in parallel. We've seen improvements to the front end since Conroe, but the overall machine width hasn't changed - even with Haswell.Haswell leaves the overall pipeline untouched. It's still the same 14 - 19 stage pipeline that we saw with Sandy Bridge depending on whether or not the instruction is found in the uop cache (which happens around 80% of the time). L1/L2 cache latencies are unchanged as well. Since Nehalem, Intel's Core micro-architectures have supported execution of two instruction threads per core to improve execution hardware utilization. Haswell also supports 2-way SMT/Hyper Threading.
The front end remains 4-wide, although Haswell features a better branch predictor and hardware prefetcher so we'll see better efficiency. Since the pipeline depth hasn't increased but overall branch prediction accuracy is up we'll see a positive impact on overall IPC (instructions executed per clock). Haswell is also more aggressive on the speculative memory access side.
The image below is a crude representation I put together of the Haswell front end compared to the two previous tocks. If you click the buttons below you'll toggle between Haswell, Sandy Bridge and Nehalem diagrams, with major changes highlighted.
Sandy Bridge introduced the 1.5K µop cache that caches decoded micro-ops. When future instruction fetch requests are made, if the instructions are contained within the µop cache everything north of the cache is powered down and the instructions are serviced from the µop cache. The decode stages are very power hungry so being able to skip them is a boon to power efficiency. There are also performance benefits as well. A hit in the µop cache reduces the effective integer pipeline to 14 stages, the same length as it was in Conroe in 2006. Haswell retains all of these benefits. Even the µop cache size remains unchanged at 1.5K micro-ops (approximately 6KB in size).
Although it's noted above as a new/changed block, the updated instruction decode queue (aka allocation queue) was actually one of the changes made to improve single threaded performance in Ivy Bridge.
The instruction decode queue (where instructions go after they've been decoded) is no longer statically partitioned between the two threads that each core can service.
The big changes in Haswell are at the back end of the pipeline, in the execution engine.
Page 7
Prioritizing ILP
Intel has held the single threaded performance crown for years now, but the why is really quite easy to understand: it has prioritized extracting instruction level parallelism with every generation. Couple that with the fact that every two years we see a "new" microprocessor architecture from Intel and there's a recipe for some good old evolutionary gains. The table below shows the increase in size of some major data structures inside Intel's architectures for every tock since Conroe:| Intel Core Architecture Buffer Sizes | ||||||
| Conroe | Nehalem | Sandy Bridge | Haswell | |||
| Out-of-order Window | 96 | 128 | 168 | 192 | ||
| In-flight Loads | 32 | 48 | 64 | 72 | ||
| In-flight Stores | 20 | 32 | 36 | 42 | ||
| Scheduler Entries | 32 | 36 | 54 | 60 | ||
| Integer Register File | N/A | N/A | 160 | 168 | ||
| FP Register File | N/A | N/A | 144 | 168 | ||
| Allocation Queue | ? | 28/thread | 28/thread | 56 | ||
This isn't rocket science, but it is enabled by Intel's clockwork fab execution. Designers can count on another 30% die area to work with every 2 years, so every 2 years they increase the size of these structures without worrying about ballooning the die. The beauty of evolutionary improvements like this is that when viewed over the long term they look downright revolutionary. Comparing Haswell to Conroe, the OoO scheduling window has grown by a factor of 2x, despite generation to generation gains of only 14 - 33%.

Page 8
Haswell's Wide Execution Engine
Conroe introduced the six execution ports that we've seen used all the way up to Ivy Bridge. Sandy Bridge saw significant changes to the execution engine to enable 256-bit AVX operations but without increasing the back end width. Haswell does a lot here.Just as before, I put together a few diagrams that highlight the major differences throughout the past three generations for the execution engine.
The reservation station holds micro-ops as they wait for the data they need to begin execution. Both of these structures grow by low double-digit percentages in Haswell.
Simply being able to pick from more instructions to execute in parallel is one thing, we haven't seen an increase in the number of parallel execution ports since Conroe. Haswell changes that.
From Conroe to Ivy Bridge, Intel's Core micro-architecture has supported the execution of up to six micro-ops in parallel. While there are more than six execution units in the system, there are only six ports to stacks of execution units. Three ports are used for memory operations (loads/stores) while three are on math duty. Over the years Intel has added additional types and widths of execution units (e.g. Sandy Bridge added 256-bit AVX operations) but it hasn't strayed from the 6 port architecture.
Haswell finally adds two more execution ports, one for integer math and branches (port 6) and one for store address calculation (port 7). Including both additional compute and memory hardware is a balanced decision on Intel's part.
The extra ALU and port does one of two things: either improve performance for integer heavy code, or allow integer work to continue while FP math occupies ports 0 and 1. Remember that Haswell, like its predecessors, is an SMT design meaning each core will see instructions from up to two threads at the same time. Although a single app is unlikely to mix heavy vector FP and integer code, it's quite possible that two applications running at the same time may produce such varied instructions. Having more integer ALUs is never a bad thing.
Also using port 6 is another unit that can handle x86 branch instructions. Branch heavy code can now enjoy two independent branch units, or if port 0 is occupied with other math the machine can still execute branches on port 6. Haswell moved the original Core branch unit from port 5 over to port 0, the most capable port in the system, so a branch unit on a lightly populated port makes helps ensure there's no performance regression as a result of the change.
Sandy Bridge made ports 2 & 3 equal class citizens, with both capable of being used for load or store address calculation. In the past you could only do loads on port 2 and store addresses on port 3. Sandy Bridge's flexibility did a lot for load heavy code, which is quite common. Haswell's dedicated store address port should help in mixed workloads with lots of loads and stores.
 Intel focused a lot on adding more execution horsepower in Haswell
without creating a power burden for legacy use cases. All of the new
units can be shut off when not in use. Furthermore, Intel went in and
ensured that this applied to the older execution units as well: in
Haswell if you're not doing work, you're not consuming power.
Intel focused a lot on adding more execution horsepower in Haswell
without creating a power burden for legacy use cases. All of the new
units can be shut off when not in use. Furthermore, Intel went in and
ensured that this applied to the older execution units as well: in
Haswell if you're not doing work, you're not consuming power.Page 9
Feeding the Beast: 2x Cache Bandwidth in Haswell
With an outright doubling of peak FP throughput in Haswell, Intel had to ensure that the execution units had ample bandwidth to the caches to sustain performance. As a result L1 bandwidth is doubled, as is the interface between the L1 and L2 caches.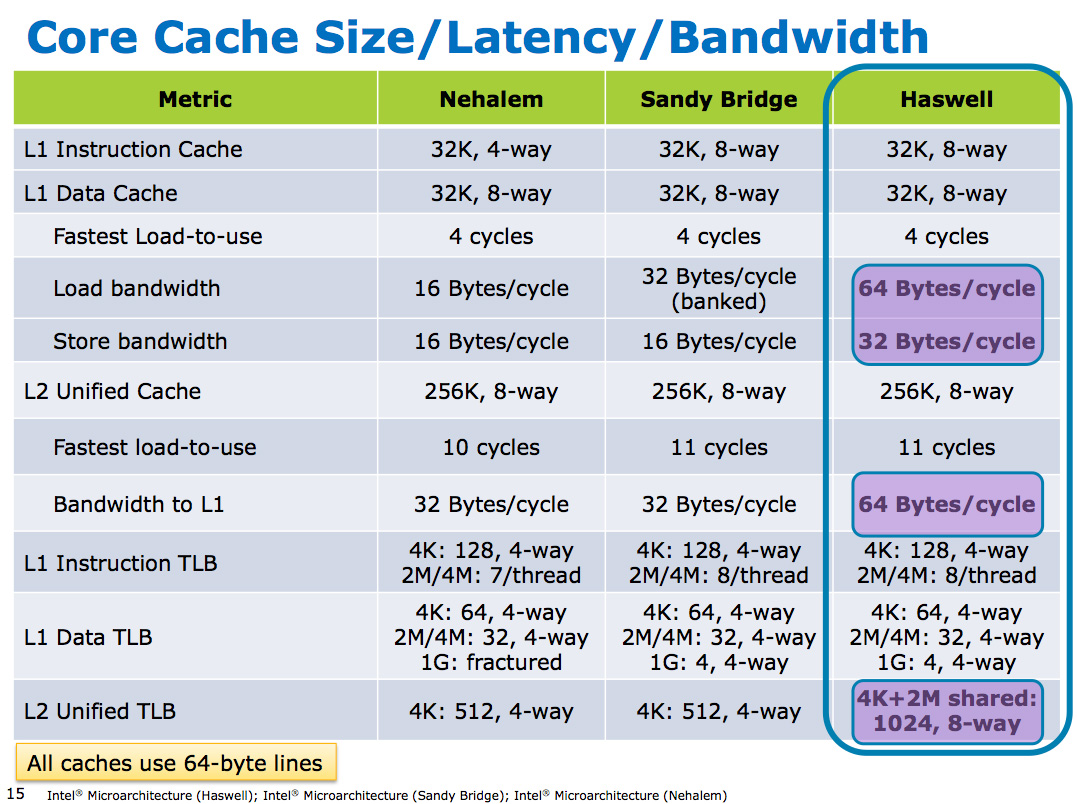
Page 10
Decoupled L3 Cache
With Nehalem Intel introduced an on-die L3 cache behind a smaller, low latency private L2 cache. At the time, Intel maintained two separate clock domains for the CPU (core + uncore) and a third for what was, at the time, an off-die integrated graphics core. The core clock referred to the CPU cores, while the uncore clock controlled the speed of the L3 cache. Intel believed that its L3 cache wasn't incredibly latency sensitive and could run at a lower frequency and burn less power. Core CPU performance typically mattered more to most workloads than L3 cache performance, so Intel was ok with the tradeoff.In Sandy Bridge, Intel revised its beliefs and moved to a single clock domain for the core and uncore, while keeping a separate clock for the now on-die processor graphics core. Intel now felt that race to sleep was a better philosophy for dealing with the L3 cache and it would rather keep things simple by running everything at the same frequency. Obviously there are performance benefits, but there was one major downside: with the CPU cores and L3 cache running in lockstep, there was concern over what would happen if the GPU ever needed to access the L3 cache while the CPU (and thus L3 cache) was in a low frequency state. The options were either to force the CPU and L3 cache into a higher frequency state together, or to keep the L3 cache at a low frequency even when it was in demand to prevent waking up the CPU cores. Ivy Bridge saw the addition of a small graphics L3 cache to mitigate this situation, but ultimately giving the on-die GPU independent access to the big, primary L3 cache without worrying about power concerns was a big issue for the design team.
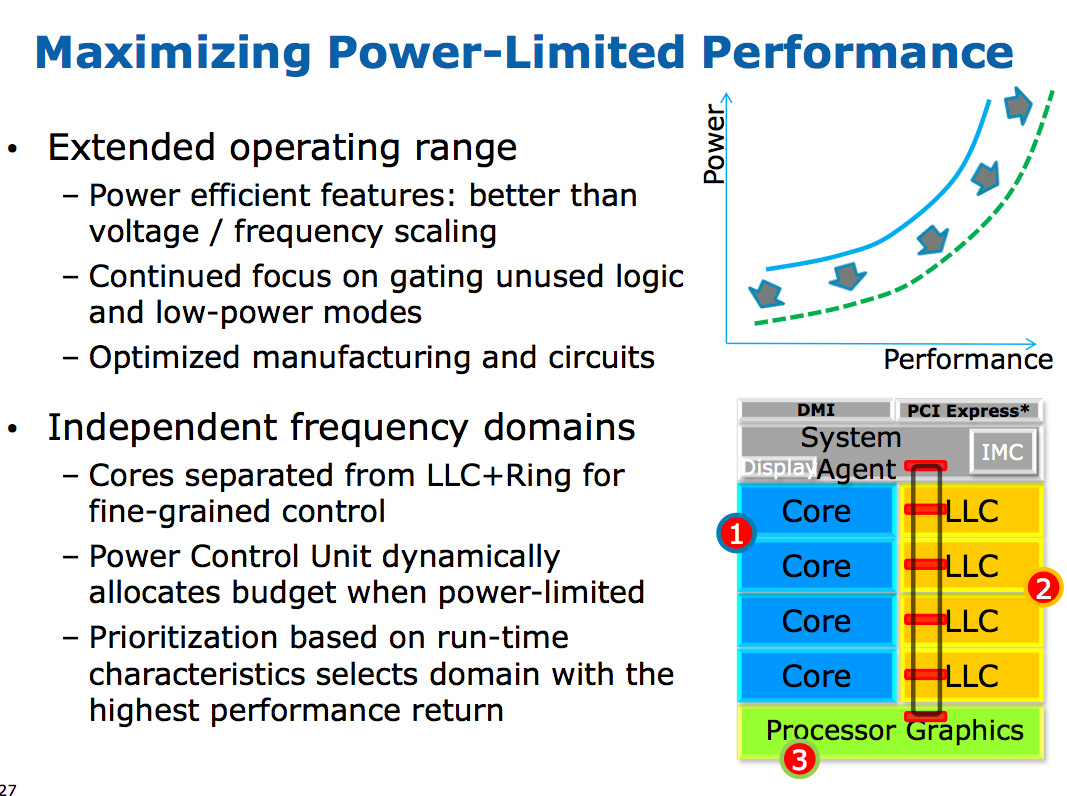
The three clock domains in Haswell are roughly the same as what they were in Nehalem, they just all happen to be on the same die. The CPU cores all run at the same frequency, the on-die GPU runs at a separate frequency and now the L3 + ring bus are in their own independent frequency domain.
Now that CPU requests to L3 cache have to cross a frequency boundary there will be a latency impact to L3 cache accesses. Sandy Bridge had an amazingly fast L3 cache, Haswell's L3 accesses will be slower.
The benefit is obviously power. If the GPU needs to fire up the ring bus to give/get data, it no longer has to drive up the CPU core frequency as well. Furthermore, Haswell's power control unit can dynamically allocate budget between all areas of the chip when power limited.
Although L3 latency is up in Haswell, there's more access bandwidth offered to each slice of the L3 cache. There are now dedicated pipes for data and non-data accesses to the last level cache.
Haswell's memory controller is also improved, with better write throughput to DRAM. Intel has been quietly telling the memory makers to push for even higher DDR3 frequencies in anticipation of Haswell.
Page 11
TSX
Johan did a great job explaining Haswell's Transactional Synchronization eXtensions (TSX), so I won't go into as much depth here. The basic premise is simple, although the implementation is quite complex.It's easy to demand well threaded applications from software vendors, but actually implementing code that scales well across unlimited threads isn't easy. Parallelizing truly independent tasks is the low hanging fruit, but it's the tasks that all access the same data structure that can create problems. With multiple cores accessing the same data structure, running independent of one another, there's the risk of two different cores writing to the same part of the same structure. Only one set of data can be right, but dealing with this concurrent access problem can get hairy.

This is by far the easiest way to deal with the problem of multiple threads accessing the same data structure, however it also prevents any performance scaling across multiple threads/cores. As focused as Intel is on increasing single threaded performance, a lot of die area goes wasted if applications don't scale well with more cores.
Software developers can instead choose to implement more fine grained locking of data structures, however doing so obviously increases the complexity of their code.



Page 12
Haswell's GPU
Although Intel provided a good amount of detail on the CPU enhancements to Haswell, the graphics discussion at IDF was fairly limited. That being said, there's still some to talk about here.Haswell builds on the same fundamental GPU architecture we saw in Ivy Bridge. We won't see a dramatic redesign/re-plumbing of the graphics hardware until Broadwell in 2014 (that one is going to be a big one).
Haswell's processor graphics extends API support to DirectX 11.1, OpenCL 1.2 and OpenGL 4.0.
At the front of the graphics pipeline is a new resource streamer. The RS offloads some driver work that the CPU would normally handle and moves it to GPU hardware instead. Both AMD and NVIDIA have significant command processors so this doesn't appear to be an Intel advantage although the devil is in the (unshared) details. The point from Intel's perspective is that any amount of processing it can shift away from general purpose CPU hardware and onto the GPU can save power (CPU cores go to sleep while the RS/CS do their job).
Beyond the resource streamer, most of the fixed function graphics hardware sees a doubling of performance in Haswell.
In Haswell GT1 and GT2 there's a single slice common, while GT3 sees a doubling of slice common. GT3 similarly has two sub-slices, although once again Intel isn't talking specifics about EU counts or clock speeds between GT1/2/3.
Now to the things that Intel didn't let loose at IDF. Although originally an option for Ivy Bridge (but higher ups at Intel killed plans for it) was a GT3 part with some form of embedded DRAM. Rumor has it that Apple was the only customer who really demanded it at the time, and Intel wasn't willing to build a SKU just for Apple.
Haswell will do what Ivy Bridge didn't. You'll see a version of Haswell with up to 128MB of embedded DRAM, with a lot of bandwidth available between it and the core. Both the CPU and GPU will be able to access this embedded DRAM, although there are obvious implications for graphics.
Overall performance gains should be about 2x for GT3 (presumably with eDRAM) over HD 4000 in a high TDP part. In Ultrabooks those gains will be limited to around 30% max given the strict power limits.
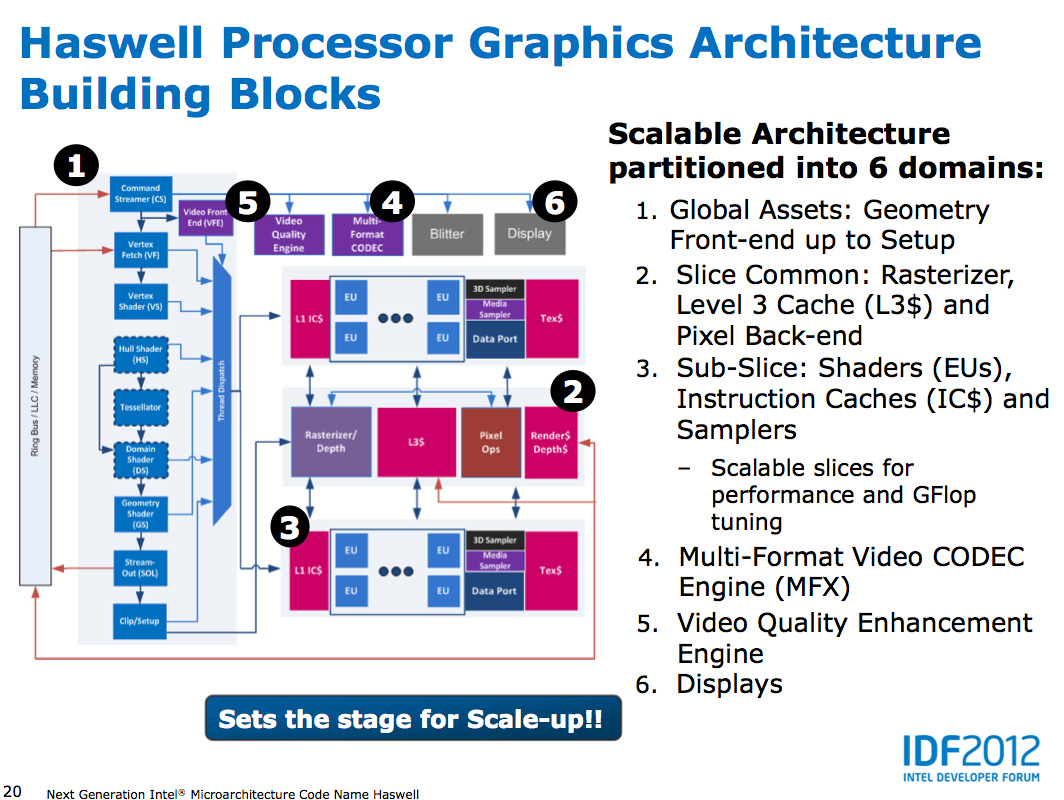
Page 13
Haswell Media Engine: QuickSync the Third
Although we still have one more generation to go before QuickSync can apparently deliver close to x86 image quality, Haswell doesn't shy away from improving its media engine.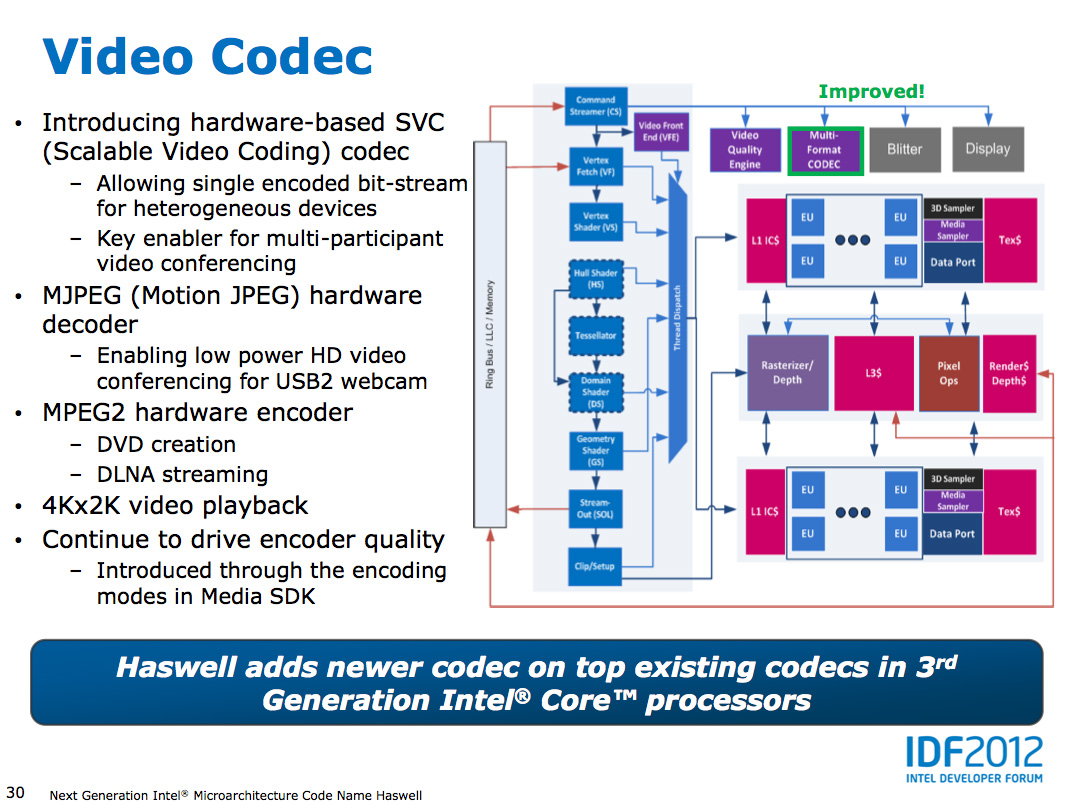
Haswell also adds a hardware motion JPEG decoder, and MPEG2 hardware encoder.
Ivy Bridge will be getting 4K video playback support later this year, Haswell should obviously ship with it.

Final Words
After the show many seemed to feel like Intel short changed us at this year's IDF when it came to architecture details and disclosures. The problem is perspective. Shortly after I returned home from the show I heard an interesting comparison: Intel detailed quite a bit about an architecture that wouldn't be shipping for another 9 months, while Apple wouldn't say a thing about an SoC that was shipping in a week. That's probably an extreme comparison given that Apple has no motivation to share details about A6 (yet), but even if you compare Intel's openness at IDF to the rest of the chip makers we cover - there's a striking contrast. We'll always want more from Intel at IDF, but I do hope that we won't see a retreat as the rest of the industry seems to be ok with non-disclosure as standard practice.
Intel's execution has been relentless since 2006. That's over half a decade of iterating architectures, as promised, roughly once a year. Little, big, little, big, process, architecture, process, architecture, over and over again. It's a combination of great execution on the architecture side combined with great enabling by Intel's manufacturing group. Haswell will continue to carry the torch in this regard.
The Haswell micro-architecture focuses primarily on widening the execution engine that has been with us, moderately changed, for the past several years. Increasing data structures and buffers inside the processor helps to feed the beast, as does a tremendous increase in cache bandwidth. Support for new instructions in AVX2 via Intel's TSX should also pave the way for some big performance gains going forward. Power consumption is also a serious target for Haswell given that it must improve performance without dramatically increasing TDP (there will be slight increases across the board for traditional form factors, while ultra portables will obviously shift to lower TDPs).
You can expect CPU performance to increase by around 5 - 15% at the same clock speed as Ivy Bridge. Graphics performance will see a far larger boost (at least in the high-end GT3 configuration) of up to 2x vs. Intel's HD 4000 in a standard voltage/TDP system. GPU performance in Ultrabooks will increase by up to 30% over HD 4000.
As a desktop or notebook microprocessor, Haswell looks very good. The architecture remains focused and delivers a sensible set of improvements over its predecessor.
Connected standby is coming to PCs and it's a truly necessary addition. Haswell's support of active idle states (S0ix) is a game changer for the way portable PCs work. The bigger concern is whether or not the OEMs and ISVs will do their best to really take advantage of what Haswell offers. I know one will, but will the rest? Intel's increasingly hands on approach to OEM relations seems to be its way of ensuring we'll see Haswell live up to its potential.
Haswell, on paper, appears to do everything Intel needs to evolve the mobile PC platform. What's unclear is how far down the TDP stack Intel will be able to take the architecture. Intel seems to believe that TDPs below 8W are attainable, but it's too early to tell just how low Haswell can go. It's more than likely that Intel knows and just doesn't want to share at this point. I don't believe we'll see fanless Haswell designs, but Broadwell is another story entirely.
There's no diagram for where we go from here. Intel originally claimed that Atom would service an expanded range of TDPs all the way up to 10W. With Core architectures dipping below 10W, I do wonder if that slide was a bit of misdirection. I wonder if, instead, the real goal is to drive Core well into Atom territory. If Intel wants to solve its ARM problem, that would appear to be a very good solution...
Source : Anand Tech
No comments:
Post a Comment